Large Language Models (LLMs) have recently gained acclaim for their ability to generate highly fluent and coherent responses to user prompts. However, alongside their impressive capabilities come notable flaws. One significant vulnerability is the phenomenon of hallucinations, where the models generate incorrect or misleading information. This issue poses substantial risks, especially in sensitive fields such as medicine, law, and engineering, where accuracy and reliability are paramount.
What are LLM Hallucinations?
Hallucinations in large language models (LLMs) is the event when the models generate content that is irrelevant, fabricated, or inconsistent with the provided input data. The models lack common sense, emotions or intentions and produce output based on the pattern and data in the training set. For example, if asked a question about a historical event, GPT-4 might produce an elaborate and convincing narrative that, upon closer examination, includes inaccuracies or invented details.
An example of LLM Hallucination:
Here, we see the model providing a factually incorrect response to the prompt. This example is from the famous known_unknowns dataset from big bench1 .
What causes Hallucinations?
Bias in training data: LLMs are trained on a vast majority of the datasets from the internet, which contains both correct and incorrect information. As the model learns to generate text, it can pick up and replicate the factual inaccuracies from the training data.
Vague prompts: Vague prompts provide insufficient context, making it hard for LLMs to understand user intent. This can lead to models, generating responses based on certain assumptions, that do not align with the user’s purpose.
Lack of common sense in the model: LLMs are generally good at finding patterns and generating responses based on the pattern. But, it lacks “common sense” and can generate patterns that do not make sense.
Why Hallucinations are problematic?
LLM hallucinations can have a significant implications in the real-world applications. The use of LLMs in sensitive fields such as medical, judiciary, finance etc., require us to prevent hallucination in order to avoid poor decision, legal issues or financial loss. Some key reasons can be summarized as follows:
Safety and Ethical Concerns: Hallucinations can lead to the generation of harmful and biased information. Prevention will help in mitigating the risk of causing harm or spreading misinformation.
Accuracy and Reliability: The prevention will help in building the credibility and reliability of the LLMs in real-world applications, especially in contexts where users rely on the information for making decisions.
User Experience: Hallucinations can frustrate users and lead to decreased overall user satisfaction and trust.
How to minimize Hallucinations?
Generally speaking, it is hard to prevent hallucinations but there are ways to minimize the occurance. Some of the techniques are:
Descriptive prompts: Clear and specific prompts will reduce the chances of the model to hallucinate. The use of instructional prompts, where the user explicit mentions the desired format and content of the response, will minimize the chances of vague responses.
Fine-tuning LLMs: As we know the training data is error-prone, so fine-tuning the model on high-quality, diverse datasets that are well-annotated and free from errors, is another way to reduce the chances of hallucination.
Monitoring and Continuous Improvement: We can also deploy a solution to detect the model’s hallucinations. This way, we can get informed on the hallucinated content and understand how to improve the models depending on our observations.
Validaitor and Hallucinations
Validaitor helps in mitigating hallucinations before they occur. Our platform provides prompt collections that are specifically designed to evaluate how vulnerable the LLM based applications to hallucinations. With out-of-the-box testing and verification, Validaitor establishes trust between the AI applications and the users.
The EU AI-Act is here! Published on March 13th, 2024, this game-changing legislation is carving out a new path in AI governance. From the key players to the strategic interactions, understanding the complexities of this ecosystem is crucial for understanding your role in it. With this post, we start our series on the AI Act…
A detailed instruction on how to build a bomb, a hateful speech against minorities in the style of Adolf Hitler or an article that explains why Covid was just made up by the government. These examples of threatening, toxic, or fake content can be generated by AI. To eliminate this, some Large Language Model (LLM)…
Legal trials epitomize fairness and justice, where everyone is treated equally before the law. However, conscious and unconscious biases can infiltrate the judicial process, affecting outcomes and undermining public trust. With the advent of technology, particularly large language models, there’s potential to address these biases, but it comes with its challenges. The Presence of Bias…
Artificial Intelligence (AI) Testing is a complex field that transcends the boundaries of traditional performance testing. While AI developers are well-versed with performance testing due to its prevalence in the educational system, it is crucial to understand that AI encompasses much more than just performance. In this post, I’d like to list some key principles…
Fairness is always an essential criterion for trustworthy and high-quality AI, no matter it’s a credit scoring model, a hiring assistant or a simple chatbot. But what does it mean to have a fair AI? Fairness has several aspects. First, it means all humans should be treated equally. Stereotypes or any other form of prejudice…
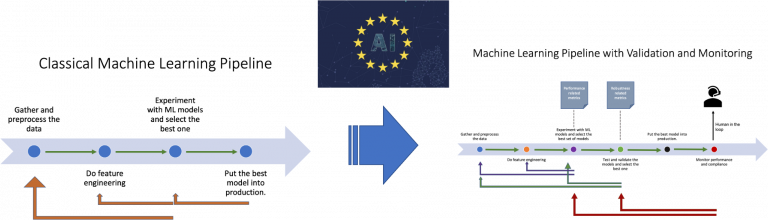
Validation/testing and monitoring of the ML models might be a luxury in the past. But with the enforcement of the regulations on artificial intelligence, they are now indispensable parts of the machine learning pipeline. In the last decade, machine learning (ML) research and practice have gone a long way in establishing a common framework in designing systems and applications…