Model Validation and Monitoring: New phases in the ML lifecycle
Validation/testing and monitoring of the ML models might be a luxury in the past. But with the enforcement of the regulations on artificial intelligence, they are now indispensable parts of the machine learning pipeline.
In the last decade, machine learning (ML) research and practice have gone a long way in establishing a common framework in designing systems and applications using machine learning models. Mostly using best practices from software engineering, the so called MLOps ecosystem also started to emerge recently. All is good and long awaited. However, two critical steps in the lifecycle of designing ML applications and services remain to be mostly untouched. That is the testing/validation and the monitoring of the ML models.
In this article, I’ll elaborate on why we need to test our ML models before going into production and how we can bring quality assurance (QA) practice into the ML space. Note that, most of the concepts I’ll talk about here are also valid for artificial intelligence (AI) systems and applications. But, since ML drives the AI developments in the last decade, I’ll be mostly talking about ML.
Throughout the article, I’ll first discuss the recent European Commission regulations on AI (in the following discussion, I refer to this as European Union regulation) and then talk about what trustworthy AI means. In investigating trustworthy AI, we’ll see problems and risks that come together with the ML models. Then I’ll try to explain why validation and monitoring are essential and how we can make our models trustworthy by adapting a suitable conceptual ML pipeline.
1. Towards regulated AI
The European Commission has recently announced that some regulations will be put forward in order to make AI applications more trustworthy. This is a very important development for AI practitioners as AI remained mostly unregulated so far with all its risks and threats. We only focused on the benefits of using AI by mostly ignoring the risks associated with it. With this regulation, companies across Europe will need to validate their “high-risk” AI systems and comply with the regulations. This is likely to spread all around the world (indeed, there’re already some regulations in UK, Canada and some states in USA). In short, EU regulations classifies AI systems according to their risk levels and makes validation and monitoring of high-risk AI systems mandatory.
EU regulation classifies an AI system as “high-risk” if the system is intended to be used in any of the 8 areas listed in the pages 4 and 5 of the Annex document or if the system poses a risk of harm to the health and safety, or a risk of adverse impact on fundamental rights. I’ll not dig into the details of the regulation in this article. Interested readers can read the full regulation proposal here. Some important concepts that are mentioned in this regulation are security, robustness and trustworthiness of these systems. Although all these concepts are intertwined and blurry in many facets, the central idea is clear: to make AI systems secure and reliable. I prefer to investigate this using “trustworthiness” as the umbrella term.
2. What is trustworthy AI?
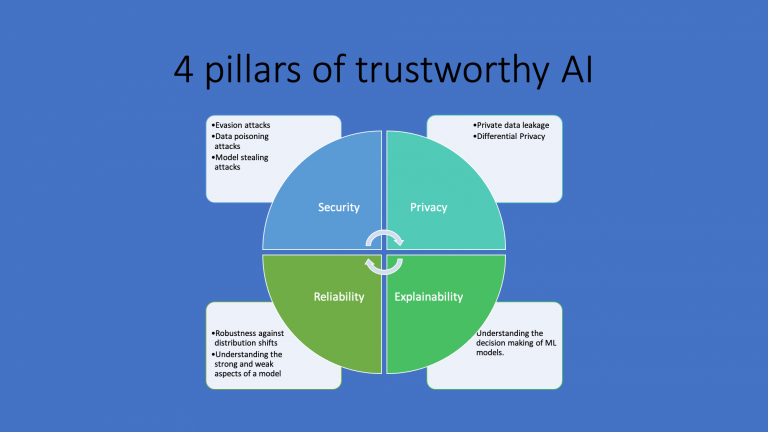
I prefer to conceptualize the trustworthy AI in four pillars. As the figure below demonstrates, it has facets like security, privacy, reliability and explainability.
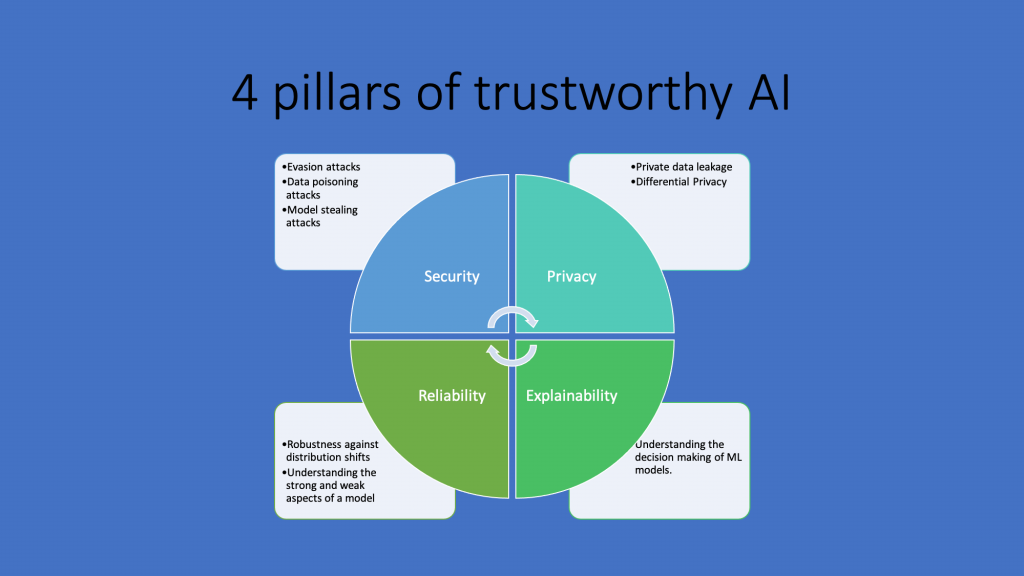
All are interrelated with each other and we’ll discuss them one by one. But before that note how European regulation mentions about some of these:
“High-risk AI systems shall be designed and developed in such a way that they achieve, in the light of their intended purpose, an appropriate level of accuracy, robustness and cybersecurity, and perform consistently in those respects throughout their lifecycle.” (EC Proposal, p.51)
2.1. Security:
The machine learning models exhibit important security vulnerabilities which enable hackers to manipulate these models, steal the private training data or leave backdoors in the models that can be triggered later on. The adversarial attack literature in the past 7 years clearly demonstrated that the attacks are really powerful and defending against them is not easy at all. All these security concerns are realizable and can have outcomes that can affect people’s health and safety.
For example, in evasion attacks, adversaries (hackers) can craft special inputs that manipulate the prediction of the ML models. They can even craft inputs so that an ML model just predicts what these attackers want! Imagine how disastrous it would be if a self-driving car increases its speed to 150 when it sees a stop sign! EU regulation makes it clear that AI models should be tested against these security issues:
“The technical solutions to address AI specific vulnerabilities shall include, where appropriate, measures to prevent and control for attacks trying to manipulate the training dataset (‘data poisoning’), inputs designed to cause the model to make a mistake (‘adversarial examples’), or model flaws.” (EC Proposal, p.52)
2.2. Privacy:
More often than not, we train our machine learning models using private data that we have or collect. This kind of data usually contains sensitive content that gives information about real people and institutions. The so called “membership inference” attacks revealed that machine learning models (especially deep learning models) tend to memorize the training data and can leak them! This means that we need to put in place the right measures to prevent our ML models leak the private data. Hence, this is a part of the model testing/validation step.
Note that some methods can be applied to the data even before we use that data to train our models. Anonymisation (!), pseudonymisation or applying a differential privacy technique might work for some cases. Even in this case the testing can be done after model training to make sure everything is in expected limits.
2.3. Reliability and fairness:
Would you ride a self-driving car without any hesitation on trusting them? Would you rely on a computer vision system that detects cancer without any consultation to a real doctor? The answers to these questions are very much related to our trust on these AI systems. We want them to be reliable so that they work consistently on every kind of circumstances they can encounter.
Understanding the strengths and weaknesses of our ML models makes us confident in trusting them. By investigating the behavior of our models in different circumstances, we can get an understanding of how our models behave. A special case of this would be to investigate the biases in the decision making process of the ML models. Understanding whether an ML model favors a group against others can help us prevent unfair predictions. Hence, checking for fairness and reliability would be in the agenda of model testing. The EU regulation puts it like this:
“To the extent that it is strictly necessary for the purposes of ensuring bias monitoring, detection and correction in relation to the high-risk AI systems, the providers of such systems may process special categories of personal data referred to in …[GDPR related regulations], subject to appropriate safeguards for the fundamental rights and freedoms of natural persons, including technical limitations on the re-use and use of state-of-the-art security and privacy-preserving measures, such as pseudonymisation, or encryption where anonymisation may significantly affect the purpose pursued.” (EC Proposal, p.48)
2.4. Explainability:
As everybody knows, deep learning models are black boxes such that we can’t really know why a model spits out a specific outcome for a given input (local interpretability). Moreover, we are not able to fully explain what our models learn from a training data (global interpretability). This lack of explainability is a major obstacle in using these models in application areas where explainability and interpretability are crucial. One set of major example is some models that are used in the financial sector where existing regulations urge them to be interpretable.
Although explainability is not something that we look for in every case, in other cases we may need it to explain why a specific outcome is predicted by an ML model. In these cases, explainability and interpretability frontiers should be investigated before putting an ML model into production. The EU regulation also makes it mandatory:
“High-risk AI systems shall be designed and developed in such a way to ensure that their operation is sufficiently transparent to enable users to interpret the system’s output and use it appropriately.” (EC Proposal, p.50)
3. How can we test/validate our machine learning models?
This brings us to the discussion of how we should test our models and validate their security, reliability, robustness etc. Unfortunately, the current ML pipeline is at its infancy in putting validation phase in a place. This is partly because security issues of the ML models are so far neglected as academic toys rather than real world scenarios. However, growing literature states that making ML models more robust against security issues also makes them more generalizable to the unseen data. Hence, putting validation at the right place in the ML pipeline is an urgent need as more and more people realize the benefits of testing the ML models.
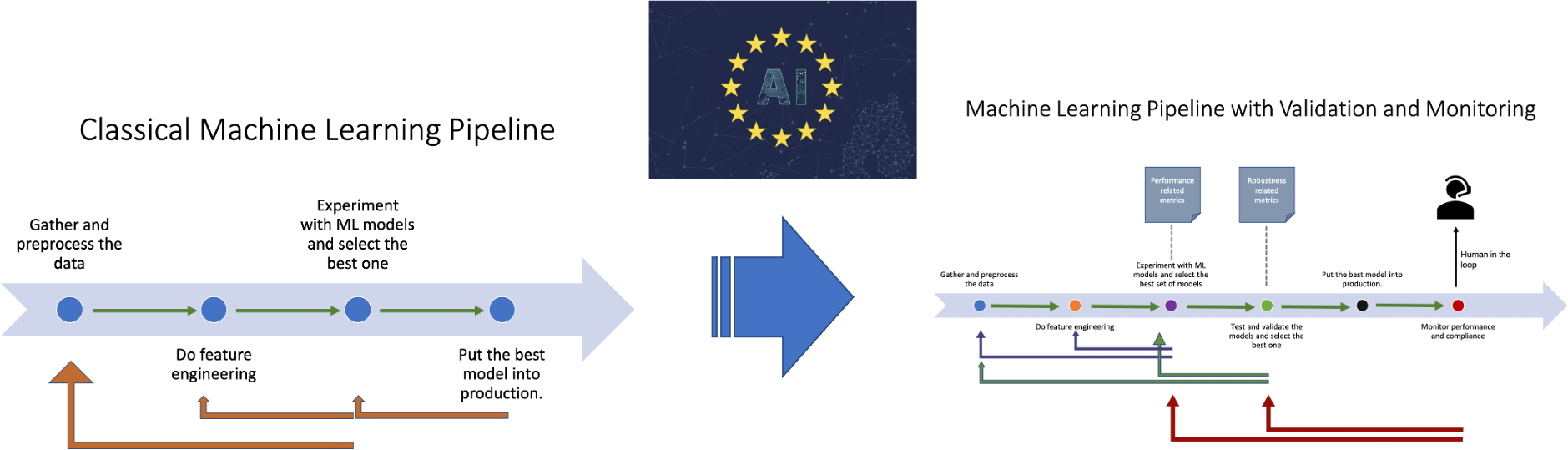
The classical ML pipeline establishes the following workflow:
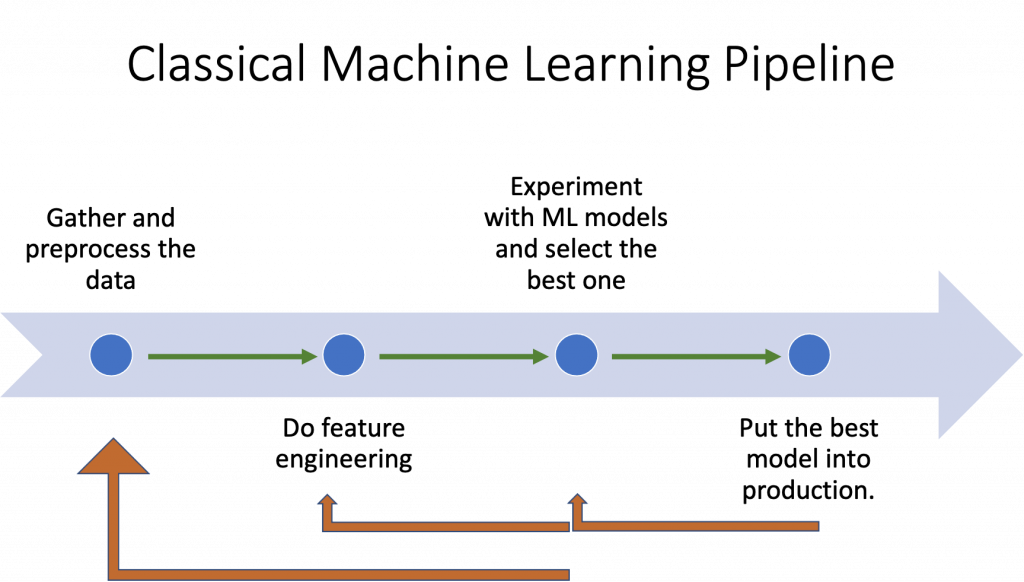
From gathering data to putting the best model into the production, this workflow is something every practitioner is more or less familiar with. So, I’ll not discuss the rationale behind this process. What I’d like to talk about is how this workflow changes when we incorporate model validation and monitoring. The machine learning pipeline with validation and monitoring phases turns into the following:
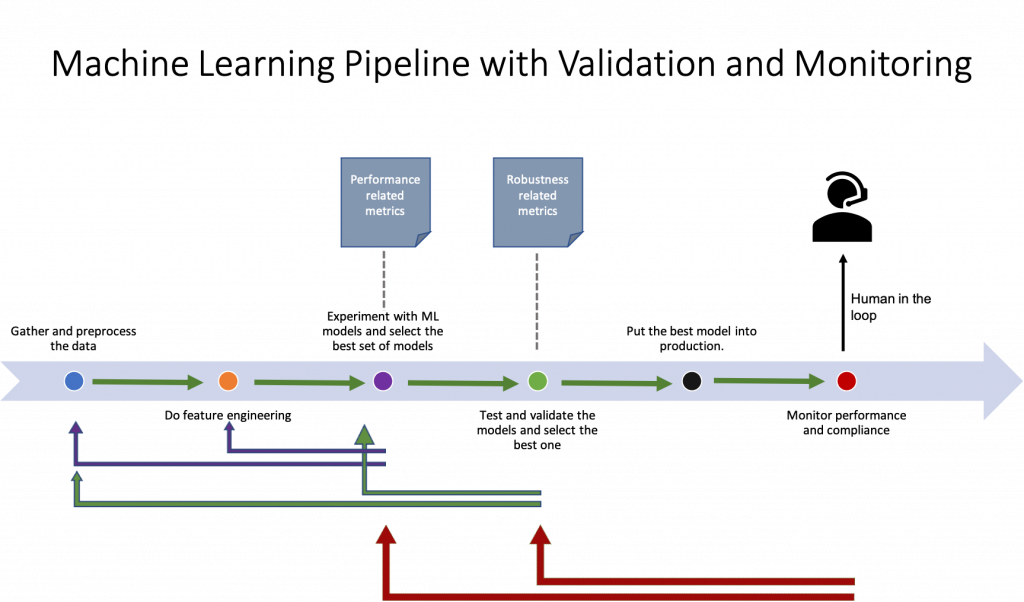
In the workflow above, we’re validating models before putting them into production and monitoring their compliance during the production. Moreover, “human oversight” is necessary for high-risk AI systems. Now, let’s try to explain each of them briefly:
3.1. Validating the models:
As we’ve touched before, machine learning models are vulnerable to adversarial attacks and may show unexpected behaviors when seeing unexpected inputs. Moreover, the fairness and bias issues may stem from data or the algorithm itself. Considering all of these, in the validation phase, we need to test our models to figure out how important these vulnerabilities and how much robust our models are. This fact brings many important points into the table.
First of all, we now need to use robustness metrics when evaluating our models and if a model falls behind a robustness benchmark, we shouldn’t put that model into the production use. This is something similar to usual performance metrics like accuracy, F1 score or something else. Now, we should consider not only the performance metrics but also the robustness metrics. This means that after we are done in selecting the best model in terms of performance metrics, we need to check its robustness. If a model passes robustness benchmarks, this means that it can be put into the production. But, what are these robustness metrics and how should we determine the robustness benchmarks? This is a vital question. However, it’s beyond the scope of this article and I’ll talk about these in a followup article.
Second, if a model fails on passing the robustness benchmarks, then the first thing to do is to try to make it more robust so that in can pass the benchmarks. There are several techniques that we can try e.g. adversarial training, differential privacy etc. However note that, these techniques are usually effective in a narrow setting and you may need to make use of many techniques to tackle with specific problems. That is to say, if our model leaks private data, then we should apply a method to prevent the data leakage. If our model is susceptible to evasion attacks, then we should use techniques like adversarial training to alleviate the problem.
Third, if we can’t resolve the robustness issues with our models, then we should consider selecting another model that is less prone to robustness problems. This entails going back to the model selection phase using performance metrics but this time eliminating the previous model. Things can get complicated here as we may need to change the model architecture or even the modeling approach.
The techniques and methods that can be used in this stage constitutes a long list. So, I’m not digging them further here but postpone to later articles on model validation methodologies and techniques. That being said, I’d like to add that the literature from adversarial attacks, data privacy, interpretability of AI and fairness are all relevant at this phase and some best practices are available to jump start.
3.2. Monitoring the models:
The story does not end with putting the best model into the production. No model is perfect and hence every model is prone to error. To be able to respond to the incidents that are dangerous or at least unexpected, we need to monitor the models that are serving in the production. This entails logging the model predictions as well as watching them closely. This is also mandatory for high-risk systems as the EU regulation puts it:
“High-risk AI systems shall be designed and developed with capabilities enabling the automatic recording of events (‘logs’) while the high-risk AI systems is operating. Those logging capabilities shall conform to recognised standards or common specifications.” (EC Proposal, p.49)
Monitoring the live models is dictated by the EU regulation and acting accordingly to the incidents that are unacceptable is mandatory. This usually requires “human in the loop” approaches where a real person should decide whether a suspected incident is acceptable or not. In some respects, this is similar to the responsibilities of a SOC (Security Operations Center) team in the cybersecurity jargon. That is, some people should monitor the behaviors of the models that are in the service. This monitoring:
- could be real-time which may be hard or even impossible in practice.
- could be regular in pre-defined periods like a day or a week.
Moreover, a feedback loop from the users of the systems should also be in place so that upon a complaint, the team should investigate the behavior of a model. In short, we need to have a concrete incident response plan!
4. Concluding Remarks
AI is and will be a regulated field of the modern technology. This fact forces the practitioners to assure the quality of their AI systems like assuring the quality of the software systems. This entails incorporating concepts like testing, validation, QA and compliance of AI systems into the service/production development pipeline. Machine learning practitioners in particular should adopt a conceptual framework that includes these phases in it. No matter what, the model validation and monitoring is already with us today and will be in the future.